Neural Network-based algorithm that was originally trained to identify breast cancer tumors on pathology slides, re-purposed to classify and extract data from document images with Deep Learning Data Extraction.
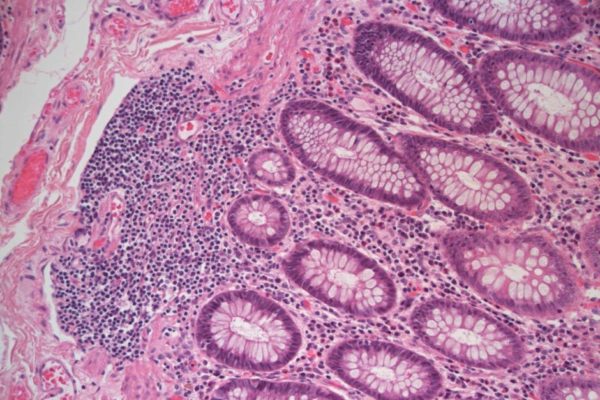
Jacksonville, FL – In late 2015, NLP Logix Lead Data Scientist, Matt Berseth, entered the company into the Camelyon16 Grand Challenge. The Camelyon16 was a challenge for the medical and computer science communities to come together to train a computer to identify breast cancer tumors, at a level at or above the highest trained pathologists in the world. In April 2016, the top five winners were announced, with the combination team of Harvard Medical School and MIT taking first place, and NLP Logix placing fifth, but as the number one commercial entrant. Little did NLP Logix know that their top performing algorithm to identify breast cancer tumors would ultimately be used for another purpose.
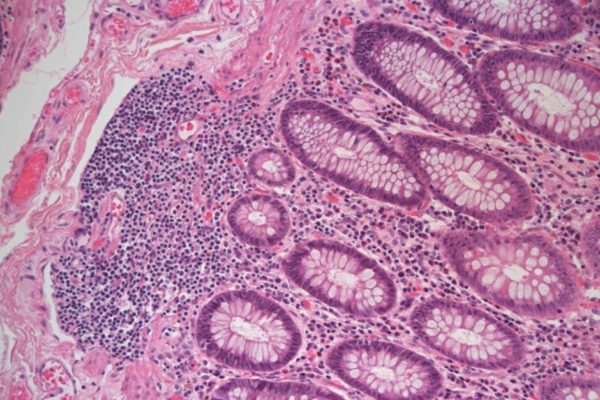
The challenge was featured in President Obama’s report on artificial intelligence in healthcare and the results have since been published in numerous healthcare and data science publications. That is the good news. The bad news is that the technology has had limited commercial success. This is unfortunate, since the results of the contest in 2016 declared that the computers had higher detection rates than the humans for the first time, making this a great advancement in medical diagnostics.
Fast forward to 2017 when a large business process outsource company learned about the contest results and asked NLP Logix if the core algorithm could be trained to identify objects in a document image, as well as classify the type of document. The answer was a resounding yes! Today, the core algorithm that was trained to identify breast cancer tumors at a level above a trained pathologist, is now identifying, extracting and classifying millions of document images.
“We worked hard to create the environment, team and technology to deliver world-class machine learning solutions, as proven by how well we did in the Camelyon16,” said Berseth. “We just never would have thought that this same core technology would be re-purposed to process document images.”
The company also felt that their approach and techniques to applying artificial intelligence to image processing was so unique that it would explore pursuing patent protection. NLP Logix contacted Wilson Dutra, a local intellectual property law firm, who conducted an extensive prior art search and confirmed that NLP Logix had really developed a novel approach.
“We were amazed how NLP Logix tackled a decades-long problem with a new and ground-breaking approach to document and image processing,” said Camille Wilson, a patent attorney at Wilson Dutra. “We quickly identified multiple innovations within the technology, and to date, NLP Logix has three issued patents, and more are expected in the future.”
NLP Logix offers the solution as Data Capture Automation and has achieved data capture rates over 40% higher than traditional optical character recognition (OCR), and accuracy rates above 95% when classifying a document type. The company has also developed a technique to identify sensitive information, like credit card numbers, social security numbers, names, etc., and blur them from the document images to support regulatory compliance.


